DataFrame Blog 2 CSV Files
Unit 1 – Data Handling I
Chapter 2
DataFrames:


Method 1: Using pandas.read_csv( csvfile_path, skiprows, names, na_values)
csvfile_path= “location of the csv file” (Saved in your system / online)
skiprows =value; is an argument that allows you to specify the number of lines to skip at the start of the file.
names = [ ‘column1 name, column2 name, column3 name [ , …….. , …..] ]
From a specified CSV file if you do not want all the columns to be the part of DataFrame then only the required column names need to be specified as an array value to the ‘names’ argument.
na_values=[‘value1’, ‘value2’[, ……] ]
In a csv file there can be a string value mentioned in a numeric column (Like AB in marks column), So such column should be treated as type int64 or float64, and missing data should be encoded as NaN so that you can apply statistics in a missing-value-friendly manner for further statistical calculations or plotting.
Example 1
import pandas
Mydf=pandas.read_csv( "/Users/vineeta/Desktop/Rough.csv")
print(" The tabular data from the file Rough is - \n ")
print(Mydf)
Example 2
import pandas
Mydf=pandas.read_csv("https://www.nseindia.com/live_market/dynaContent/liv e_watch/equities_stock_watch.htm", names= [ ‘Symbol’, ‘Open’, ‘High’, ‘Low’, ‘Close’] )
print(" The Stock_data from NSE web site for August 24, 2020 is - \n \n ")
print(Mydf)
import pandas as pd
import numpy as np
Mydf=pd.read_csv( "E:\Stock_Data.csv", skiprows=1, names=[ 'Symbol', 'Open', 'High', 'Low', 'Close' ] )
print(" The Stock_data from NSE web site for October 13, 2019 is - \n \n ", Mydf)
highe=Mydf.max( )
lowe= Mydf.min( )
print(" \n The highest stock for the day is = \n", highe)
print(" \n The lowest stock for the day is = \n", lowe)

The Stock_data from NSE web site for October 13, 2019 is -
Symbol Open High Low Close
0 NIFTY 50 11,919.45 11,958.85 11,881.75 11,940.10
1 INFRATEL 227.95 259.85 227.7 251.65
2 BHARTIARTL 426.9 445.65 421.45 444.65
3 AXISBANK 725 750.2 725 749.8
4 RELIANCE 1,467.00 1,514.90 1,465.00 1,511.55
5 POWERGRID 191 196 190.2 195.95
6 CIPLA 461.2 477.5 459.55 473.3
7 GRASIM 775 793.5 772 789
8 SBIN 325.8 331.8 322.1 331.4
9 TECHM 754 766 752 763.25
10 INDUSINDBK 1,382.00 1,409.00 1,374.55 1,395.00
11 EICHERMOT 21,600.00 21,799.95 21,424.20 21,780.05
12 INFY 709.9 714 705 712.8
13 HDFCBANK 1,265.30 1,275.00 1,261.10 1,274.75
14 IOC 132.4 133.6 131.75 133.5
15 BAJAJFINSV 9,070.00 9,189.00 9,066.30 9,163.00
16 DRREDDY 2,741.00 2,760.45 2,724.50 2,751.00
17 TITAN 1,158.80 1,167.80 1,153.10 1,164.00
18 WIPRO 248.2 251.15 247.7 250.45
19 GAIL 124.7 125.8 123.15 125.3
20 LT 1,364.50 1,378.20 1,361.50 1,369.50
21 UPL 551 556.75 538.1 550.2
22 SUNPHARMA 425 429.9 421.6 425.2
23 NESTLEIND 14,110.00 14,211.90 14,009.60 14,100.00
24 NTPC 117.75 118.3 116.8 117.5
25 BAJAJ-AUTO 3,156.00 3,171.50 3,122.10 3,156.30
26 HINDALCO 193.6 194 190.65 193.25
27 BPCL 520.65 521.9 513.5 520.7
28 KOTAKBANK 1,629.90 1,631.10 1,614.15 1,623.00
29 COALINDIA 200.95 201.3 198.25 199.75
30 BAJFINANCE 4,165.00 4,182.15 4,126.25 4,140.00
31 ADANIPORTS 367.5 368.15 361.55 364
32 BRITANNIA 3,140.90 3,158.35 3,110.00 3,124.50
33 ONGC 135 135.1 132.8 133.1
34 ITC 251.75 251.8 248.8 249.25
35 HCLTECH 1,139.00 1,143.50 1,128.65 1,133.90
36 MARUTI 7,146.00 7,155.00 7,032.00 7,054.00
37 JSWSTEEL 249.4 250.85 246.6 248
38 ULTRACEMCO 4,130.00 4,130.00 4,085.25 4,097.00
39 VEDL 143.75 143.9 140.4 142.3
40 ICICIBANK 497.95 502 489.85 494.3
41 HINDUNILVR 2,060.05 2,060.05 2,030.00 2,039.00
42 HDFC 2,235.60 2,238.75 2,202.20 2,215.70
43 ASIANPAINT 1,747.95 1,748.00 1,718.50 1,723.00
44 HEROMOTOCO 2,520.00 2,520.00 2,463.10 2,473.00
45 TATAMOTORS 170.8 171.75 167.1 167.9
46 TATASTEEL 414 414.85 400 403
47 TCS 2,153.00 2,154.65 2,105.00 2,110.00
48 ZEEL 293.75 293.75 282.5 288
49 M&M 573.75 575 559.65 561
50 YESBANK 65 67.25 63.05 64.2
The highest stock for the day is =
Symbol EICHERMOT
Open 21,780.05
High 21,799.95
Low 21,424.20
Close 21,600.00
dtype: object
The lowest stock for the day is =
Symbol YESBANK
Open 64.2
High 67.25
Low 63.05
Close 65
dtype: object



sample={'Employee' : ['Amitej', 'Prakhar', 'Naman', 'Amitej', 'Prakhar'],
'Payable Amount':[10000, 12000, 14000, 20000, 15000]}
mydf=pd.DataFrame(sample)
print(mydf)
print("\nIterating over rows using index attribute :\n")
for i in mydf.index:
print(mydf['Employee'][i])
print()
for i in range(len(mydf)) :
print(mydf.loc[i, "Employee"])
print()
for i in range(len(mydf)) :
print(mydf.iloc[i, 0])
executable statement(s)
# row is the fixed keyword with initial row index value which keeps iterating (increases by 1)
# rowSeries is the keyword which extracts the data for each column along with column heading of the current row index
Eg- for (row, rowSeries) in mydf1.iterrows( ):
print(“Row Index – ”, row, “ & its record is – ” rowSeries)

iteritems( ): - is the method / function which shows data of a dataframe column / item wise.
Syntax – for (col, colSeries) in dataframeobjectname.iteritems( ):
executable statement(s)
#col is the keyword with default column index value which keeps iterating
#colSeries is the keyword which extracts the data for each row along with row heading of the current column index
#and the loop iterates from the initial value (0) of index to the last index value
Eg -- Same main program code to continue (Mydf1)
for (col, colSeries) in Mydf1.iteritems( ):
print(“Column Index – ”, col, “ & its each data item is –”, colSeries)

pandas.pivot_table( ) - is the method of pandas which allows to create a subset of a dataframe as what like pandas.pivot( )
The advantages of using pandas.pivot_table( ) is
*
removes the chances of duplicity of data (how?)
* contains count(), sum() and table related functions
* converts row to column (vice versa)
Syntax – pandas.pivot_table(DataFrame, values=None, index=None, columns=None, aggfunc=‘funckeyword’, fill_value=None, dropna=True)
Primary parameters/ arguments are – index, values and aggfunc
#values – assign the column to be aggregated
#index - is assigned with a column / array / list
#columns - is assigned with a column / array / list
#aggfunc – is the aggregation keyword to be applied
#fil_value - is assigned with a default value which appears when values do not match
#dropna-is assigned with true/false(default) and if true results in dataframe with dropped
rows with missing values
Example 1 -
import pandas as pd
sample={
‘Employee’ : [‘Amitej’, ‘Prakhar’, ‘Naman’, ‘Amitej’, ‘Prakhar’],
‘Payable Amount’ :[10000, 12000, 14000, 20000, 15000]
} #creating a dictionary named sample
mydf2=pd.DataFrame(sample) #dataframe is created through dictionary
print(mydf2) O/P 1
newtable=pd.pivot_table(mydf2, index=[‘Employee’], aggfunc=numpy.sum)
print(newtable) O/P 2
O/P 1
Employee Payable Amount
0 Amitej 10000
3 Amitej 20000
4 Prakhar 15000
O/P 2
Employee Payable Amount
Amitej 30000
Prakhar 27000
Naman 14000
** index value is now the Employee column’s value
Example 2
Data of the CSV File Employee.csv

Code to create a pivoted table from the Employee.csv file
import pandas as pd
import numpy
mydf1=pd.read_csv(“..\DataFrames\Employee.csv, skiprows=1, names=
[ 'Code', 'Name', 'Week', 'Amount Payable'])
print(mydf1)
pivotedtable=mydf1.pivot_table(mydf1, index=[“Name”], aggfunc=numpy.sum)

** Creating a Data Frame without any data ????????
Generate an array / a table of random numbers -
numpy.random.randint(0,100)
array = numpy.random.randint(0,100,size=(10,4))
Convert this table / matrix / array into a dataframe
Mydf1 = pandas.DataFrame(array)
Convert this data frame to a csv file or from this dataframe create a csv file named try.csv
Mydf1.to_csv('try.csv')
Example 1 -
import numpy
array = numpy.random.randint(0,100,size=(4,4))
print(array)
Mydf1 = pandas.DataFrame(array, columns = ['Eng', 'Maths', 'Chem','Acc'])
print("\n", Mydf1)
Mydf1.to_csv('try.csv')

Create a second dataframe likewise
import numpy
array = numpy.random.randint(0,100,size=(4,5))
print(array)
Mydf2 = pandas.DataFrame(array, columns = ['Eng', 'Maths', 'Chem','Acc', 'Eco'])
print("\n", Mydf2)
Mydf1.to_csv('try2.csv')







Adding a row and dataframes in a dataframe created through a csv file
pandas.concat( )
pandas.concat([row_value, dataframe_object]).reset_index(drop)
OR
pandas.concat([dataframe_objects], axis, join, join_axes[ ] , ignore_index)
row_value - is the new row value for a predefined dataframe which has to be added.
dataframe_object - is the dataframe in which a new row has to be added.
reset_index(drop) - is the method of the concat( ) which allows to reset the index address values of the new dataframe.
axis - default value is 0 (0 / 1) which means adding of the new row will be row wise.
join - default value is 'outer' ('outer' / 'inner' ) where outer is for union between the dataframe objects and inner for the intersection of the dataframe objects.
join_axes[ ] - replaces the indexes of the dataframes with a new set of indexes, ignoring their actual index and if one of the dataframes is longer than the corresponding index, then that particular index will be truncated in the resultant dataframe.
import pandas as pd
Mydf = pd.read_csv("https://www.nseindia.com/live_market/dynaContent/live_watch/equities_stock_watch.htm")
new_row = pd.DataFrame( { 'Symbol':'SIB', 'Open':1200.50, 'High':350, 'Low':220, 'Age':33, 'Close': 250}, index =[0])
# simply concatenate both dataframes
Mydf2 = pd.concat([new_row, Mydf]).reset_index(drop = True)
print(Mydf2)
To concatenate the dataframes as one dataframe -
Mydf1
Mydf2
Mydf3
Listdf = [ Mydf1, Mydf2, Mydf3 ]
Finaldf = pandas.concat(Listdf)
Let's try to answer some questions seeing the below image


This can be achieved by the argument 'keys' of the pandas.concat( )



Add New Column to Dataframe
Pandas allows to add a new column to an existing dataframe in various ways -
1. By directly assigning the new column with a value to the dataframe.
a. Mydf1['Percentage'] = 90
b. Mydf1['Rank'] = pandas.Series(['Third', 'Fifth' , 'First', 'Second', 'Fourth'])
c. Mydf1['Total Marks'] = Mydf1['M1'] + Mydf1['M2'] + Mydf1['M3']
2. pandas_object.assign(Column_name = List_obj)
We want to add the new column named Rank with the values - 'Third', 'Fifth' , 'First', 'Second', 'Fourth' respectively to our existing dataframe.
rank=['Third', 'Fifth' , 'First', 'Second', 'Fourth']
Mydf1.assign(Rank=rank)
Add Multiple Columns to a Dataframe
Let's add these two list (Date, City) as column to the existing dataframe using assign with a dict of column names and values
Date = ['1/9/2017','2/6/2018','7/12/2018', '5/11/2018', '3/7/2018', '4/8/2018' ]
City = ['SFO', 'Chicago', 'Charlotte', 'Santiago', 'Hollywood']
Mydf1.assign({'City' : City, 'Date' : Date})
3. pandas.insert( )
Pandas insert( ) method allows the user to insert a column in a dataframe or series(1-D Data frame) at the specified location.
A column can also be inserted manually in a data frame by the following method, but there isn’t much freedom here.
For example, even column location can’t be decided and hence the inserted column is always inserted in the last position.
DataFrameName.insert(loc, column, value, allow_duplicates = False)
loc: loc is an integer which is the location of column where we want to insert new column. This will shift the existing column at that position to the right.
column: column is a string which is name of column to be inserted.
value: value is simply the value to be inserted. It can be int, string, float or anything or even series / List of values. Providing only one value will set the same value for all rows.
allow_duplicates : allow_duplicates is a boolean value which checks if column with same name already exists or not.
# inserting new column with values of list made above
date_of_birth=['04/04/2004', '05/05/2005', .......]
Mydf1.insert(2, "D-o-B", date_of_birth)
Create a new column in Pandas DataFrame based on the existing columns
Create a Dataframe containing data about an event, we would like to create a new column called ‘Discounted_Price’, which is calculated after applying a discount of 10% on the Ticket price.
DataFrame.apply() function can be used to achieve this task.
# importing pandas as pd
import pandas as pd
# Creating the DataFrame
df = pd.DataFrame({'Date':['10/2/2011', '11/2/2011', '12/2/2011', '13/2/2011'],
'Event':['Music', 'Poetry', 'Theatre', 'Comedy'],
'Cost':[10000, 5000, 15000, 2000]})
# Print the dataframe
print(df)
Now we will create a new column called ‘Discounted_Price’ after applying a 10% discount on the existing ‘Cost’ column.
# using apply function to create a new column
df['Discounted_Price'] = df.apply(lambda row: row.Cost -(row.Cost * 0.1), axis = 1)
# Print the DataFrame after addition
# of new column
print(df)
** Pandas DataFrame.columns attribute return the column labels of the given Dataframe.
print(dataframe_obj.columns)
** Pandas DataFrame.sort_values( )
# Sort the rows of dataframe by 'Name' column
rslt_df = dataframe_obj.sort_values(by = 'Name')
rslt_df = dataframe_obj.sort_values(by = ['Name', 'Age'])
# column in Descending Order
rslt_df = dataframe_obj.sort_values(by = 'Name', ascending = False)
Create an empty DataFrame with some column names and indices and then appending rows one by one to it using loc[ ] attribute.
# import pandas library as pd
import pandas as pd
# create an Empty DataFrame object with
# column names and indices
df = pd.DataFrame(columns = ['Name', 'Articles', 'Improved'], index = ['a', 'b', 'c'])
print("Empty DataFrame With NaN values : \n\n", df)
# adding rows to an empty
# dataframe at existing index
df.loc['a'] = ['Ankita', 50, 100]
df.loc['b'] = ['Ankit', 60, 120]
df.loc['c'] = ['Harsh', 30, 60]
print(df)
Get minimum of each column from a dataframe
df = pd.DataFrame(data, index = ['a', 'b', 'c', 'd', 'e'],
columns = ['x', 'y', 'z'])
minvalue_series = df.min()
Use min() function on a dataframe with ‘axis = 1’ attribute to find the minimum value over the row axis.
minvalue_series = df.min(axis = 1)
4. pandas.merge(dataframe_objects, how= 'inner', on= None, sort= 'True')
Dataframe objects
On - Column or index level names to join on. Must be found in each of the DataFrame objects. If not passed and left_index andright_index are False, the intersection of the columns in the DataFrames will be inferred to be the join keys.
how - The how argument to merge specifies how to determine which keys are to be included in the resulting table. If a key combination does not appear in either the left or right tables, the values in the joined table will be NA. Here is a summary of the how options and their SQL equivalent names:
| Merge Values | SQL Join Name | Description |
|---|---|---|
left | LEFT OUTER JOIN | Use keys from first dataframe only |
right | RIGHT OUTER JOIN | Use keys from second dataframe only |
outer | FULL OUTER JOIN | Use union of keys from both dataframes |
inner | INNER JOIN | Use intersection of keys from both dataframes |
Now, suppose, if we want to merge two dataframes say left and right and the keys should be used only from the first dataframe.
result=pandas.merge(left, right, on= 'key1 )

Now, when dataframes have more than one keys in each then how to merge theses dataframes -
result=pandas.merge(left, right, on= [ 'key1, 'Key2' ] )

Now, Merging the dataframes with different 'how' values like merging on the keys of first dataframe only.
result=pandas.merge(left, right, how='left', on= [ 'key1, 'Key2' ] )

Now, Merging the dataframes on the keys of second dataframe only
result=pandas.merge(left, right, how='right', on= [ 'key1, 'Key2' ] )

Now, Merging the dataframes on the keys of both the dataframes as union operation (all the rows and columns)
result=pandas.merge(left, right, how='outer', on= [ 'key1, 'Key2' ] )

Now, Merging the dataframes on the keys of both the dataframes as inner operation (intersection)
result=pandas.merge(left, right, how='inner', on= [ 'key1, 'Key2' ] )

Deleting a Column from a Dataframe
del dataframe_obj[ 'Coulmn_name'] - del keyword will delete the entire content of the specified column from the dataframe.
dataframe_obj.pop('Column_name') - will delete the particular specified column and will aso show the delted column with the values.
dataframe_obj.drop('index_name', 'Column_name', axis) - will show the new dataframe with the columns which have not been deleted.
Whether to drop labels from the index (0 or ‘index’) or columns (1 or ‘columns’).
Alternative to specifying axis (labels, axis=0 is equivalent to index=labels).
Alternative to specifying axis (labels, axis=1 is equivalent to columns=labels).
Example -
import pandas as pd
DictofSeries={ 'Subject1': pd.Series([90, 100, 90, 99], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject2': pd.Series([80, 90, 85, 90], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject3': pd.Series([100, 80, 95, 89], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject4': pd.Series([85, 70, 75, 70], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject5': pd.Series([90, 80, 80, 95], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
}
Mydf=pd.DataFrame(DictofSeries)
print("\nDataframe from Dictionary of Series \n",Mydf)
d1=Mydf.drop(['Abhishek'])
print("\n", d1)
d2=d1.drop(['Subject5'], axis=1)
print("\n", d2)
d3=d2.drop(columns='Subject4')
print("\n", d3)

Example 2- 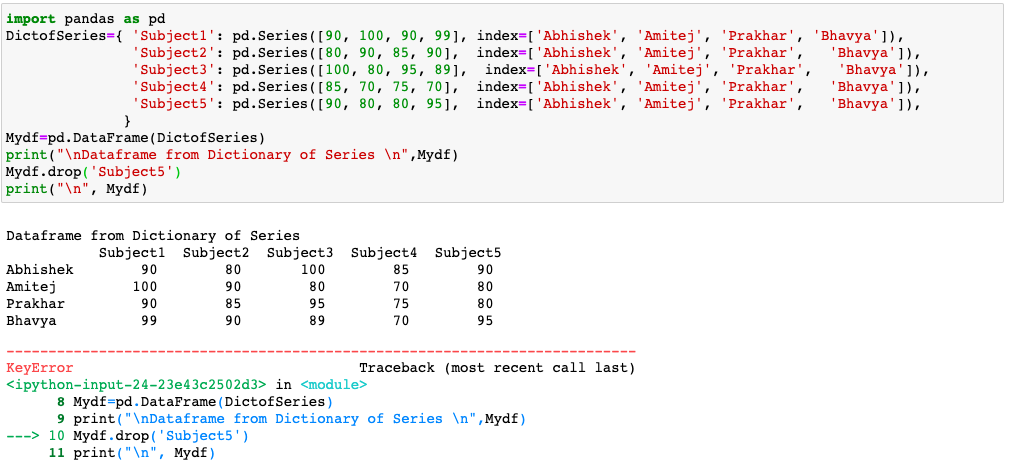
KeyError: "['Subject5'] not found in axis"import pandas as pd
Term1={ 'Subject1': pd.Series([90, 100, 90, 99], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject2': pd.Series([80, 90, 85, 90], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject3': pd.Series([100, 80, 95, 89], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject4': pd.Series([85, 70, 75, 70], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Grades': pd.Series(['A', 'B', 'B', 'C'], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
}
T1df=pd.DataFrame(Term1)
print("\nDataframe1 from Dictionary of Series \n", T1df)
Term2={ 'Subject1': pd.Series([100, 100, 100, 99], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject2': pd.Series([90, 90, 100, 90], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject3': pd.Series([90, 80, 95, 89], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject4': pd.Series([85, 75, 80, 70], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Grades': pd.Series(['A', 'A', 'B', 'C'], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
}
T2df=pd.DataFrame(Term2)
print("\nDataframe2 from Dictionary of Series \n", T2df)


Adding two columns of two different dataframes -
import pandas as pd
Term1={ 'Subject1': pd.Series([90, 100, 90, 99], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject2': pd.Series([80, 90, 85, 90], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject3': pd.Series([100, 80, 95, 89], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject5': pd.Series([85, 70, 75, 70], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Grades': pd.Series(['A', 'B', 'B', 'C'], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
}
T1df=pd.DataFrame(Term1)
print("\nDataframe1 from Dictionary of Series \n", T1df)
Term2={ 'Subject1': pd.Series([100, 100, 100, 99], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject2': pd.Series([90, 90, 100, 90], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject3': pd.Series([90, 80, 95, 89], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Subject4': pd.Series([85, 75, 80, 70], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
'Grades': pd.Series(['A', 'A', 'B', 'C'], index=['Abhishek', 'Amitej', 'Prakhar', 'Bhavya']),
}
T2df=pd.DataFrame(Term2)
print("\nDataframe2 from Dictionary of Series \n", T2df)
dfnew=T1df['Subject5']+T2df['Subject4']
print("The 2 added column is \n", dfnew)
The O/P --
The 2 added column is Abhishek 170 Amitej 145 Prakhar 155 Bhavya 140 dtype: int64

Further you can use this column in any of the existing dataframe / Add / Relpace
T2df['Subject4']=dfnew
print(T2df)
dfnew=T1df['Subject5']+T2df['Grades']
print("The difference of the columns = \n", dfnew)
TypeError: unsupported operand type(s) for +: 'int' and 'str'Reminder
If you want to create a third column from adding two columns -
1. df['C'] = df['A'] + df['B']
2. df['C'] = df.sum(axis=1)
3. df['C'] = df.apply(lambda row: row['A'] + row['B'], axis=1)
4. df.assign(C = df.A + df.B)
2. subtraction - to find or calculate the differences.
' - ' - operator
print(T1df-T2df)
O/P-
TypeError: unsupported operand type(s) for -: 'str' and 'str'
sub( ) - method
TypeError: unsupported operand type(s) for -: 'str' and 'str'dfnew=T1df['Subject5']-T2df['Subject4']
print("The difference of the columns = \n", dfnew)

3. product / multiplication -
'*'
mul( )
4. division / quotient -
'/'
div( )
5. right side addition -
radd( )
print(T1df.radd(T2df))

6. right side subtraction -
TypeError: unsupported operand type(s) for -: 'str' and 'str'
Indexing using Labels
To select a column by its label, we use the .loc[ ] attribute.
** Integers are valid labels, but they refer to the label and not the position.
loc[ ] takes two single/list/range operator separated by ','. The first one indicates the row and the second one indicates columns.
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) #select all rows for a specific column print(df.loc[:,'A'])
a 0.391548 b -0.070649 c -0.317212 d -2.162406 e 2.202797 f 0.613709 g 1.050559 h 1.122680 Name: A, dtype: float64
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # Select all rows for multiple columns, say list[] print(df.loc[:,['A','C']])
Output -
A C a 0.391548 0.745623 b -0.070649 1.620406 c -0.317212 1.448365 d -2.162406 -0.873557 e 2.202797 0.528067 f 0.613709 0.286414 g 1.050559 0.216526 h 1.122680 -1.621420
# import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4),
index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D'])
# Select few rows for multiple columns, say list[]
print(df.loc[['a','b','f','h'],['A','C']])
Output −
A C
a 0.391548 0.745623
b -0.070649 1.620406
f 0.613709 0.286414
h 1.122680 -1.621420
Indexing range of rows for all columns of a dataframe -
# import the pandas library and aliasing as pd
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4),
index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D'])
# Select range of rows for all columns
print(df.loc['a':'h'])
Output -
A B C D
a 0.391548 -0.224297 0.745623 0.054301
b -0.070649 -0.880130 1.620406 1.419743
c -0.317212 -1.929698 1.448365 0.616899
d -2.162406 0.614256 -0.873557 1.093958
e 2.202797 -2.315915 0.528067 0.612482
f 0.613709 -0.157674 0.286414 -0.500517
g 1.050559 -2.272099 0.216526 0.928449
h 1.122680 0.324368 -1.621420 -0.741470


BoolBoolean Indexing







{kind=link}
Comments
Post a Comment